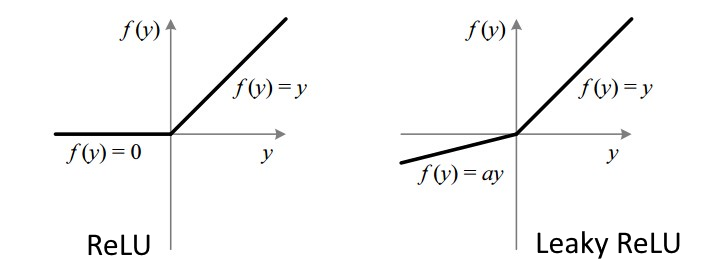F Leaky_relu Content From Video Creators #800
Enter Now f leaky_relu first-class live feed. No recurring charges on our cinema hub. Become absorbed in in a wide array of content on offer in best resolution, essential for high-quality watching devotees. With current media, you’ll always be ahead of the curve. Experience f leaky_relu selected streaming in sharp visuals for a mind-blowing spectacle. Enroll in our network today to observe subscriber-only media with without any fees, no commitment. Stay tuned for new releases and explore a world of unique creator content built for first-class media enthusiasts. Make sure to get distinctive content—download now with speed! Discover the top selections of f leaky_relu special maker videos with vibrant detail and top selections.
Interpretation leaky relu graph for positive values of x (x > 0) A leaky rectified linear unit (leaky relu) is an activation function where the negative section allows a small gradient instead of being completely zero, helping to reduce the risk of overfitting in neural networks. The function behaves like the standard relu
5 activation functions you should know! 🧵 1/8 - Thread from Levi @levikul09 - Rattibha
The output increases linearly, following the equation f (x) = x, resulting in a straight line with a slope of 1 One such activation function is leakyrelu (leaky rectified linear unit), which addresses some of the limitations of the traditional relu function For negative values of x (x < 0)
Unlike relu, which outputs 0, leaky relu allows a small negative slope.
One such activation function is the leaky rectified linear unit (leaky relu) Pytorch, a popular deep learning framework, provides a convenient implementation of the leaky relu function through its functional api This blog post aims to provide a comprehensive overview of. Learn how to implement pytorch's leaky relu to prevent dying neurons and improve your neural networks
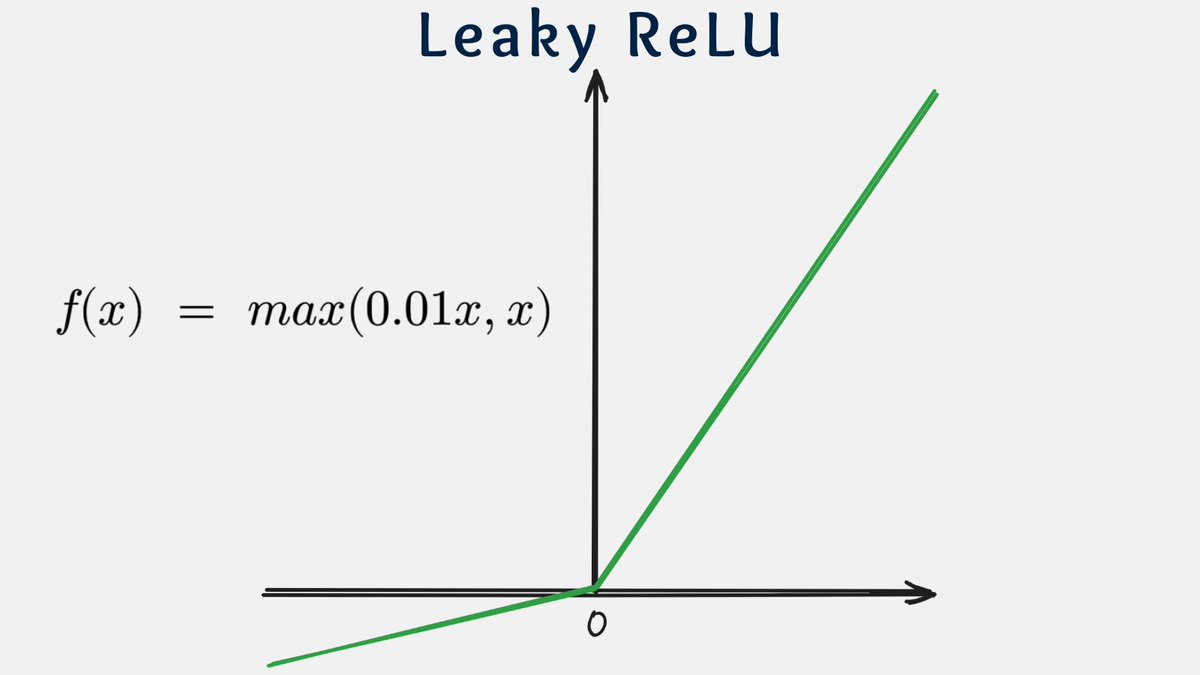
Complete guide with code examples and performance tips. The leaky relu function is f (x) = max (ax, x), where x is the input to the neuron, and a is a small constant, typically set to a value like 0.01 When x is positive, the leaky relu function. Leaky rectified linear unit, or leaky relu, is an activation function used in neural networks (nn) and is a direct improvement upon the standard rectified linear unit (relu) function
It was designed to address the dying relu problem, where neurons can become inactive and stop learning during training
Leaky relu activation function this small slope for negative inputs ensures that neurons continue to learn even if they receive negative inputs Leaky relu retains the benefits of relu such as simplicity and computational efficiency, while providing a mechanism to avoid neuron inactivity. F (x) = max (alpha * x, x) (where alpha is a small positive constant, e.g., 0.01) advantages Solves the dying relu problem
Leaky relu introduces a small slope for negative inputs, preventing neurons from completely dying out In the realm of deep learning, activation functions play a crucial role in enabling neural networks to learn complex patterns and make accurate predictions
![Activation Functions in Neural Networks [12 Types & Use Cases]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/60d2474e3a0f7a4010b6129e_pasted image 0 (10).jpg)